CASE STUDY | TECHNICAL SEO | MALWARE RECOVERY
How I diagnosed, contained, and reversed a malware-driven index pollution on a WordPress site, using a deliberate four-phase sequence.
20,000+
Fraudulent URLs indexed at peak
138,000+
Additional URLs blocked before indexing
0
Malicious URLs remaining at close
CONTEXT
The site is a personal project, a travel agency I built and manage on WordPress. After migrating from a local development environment to a live hosting provider, I noticed anomalies in Google Search Console, a sudden spike in indexed pages far beyond the actual content of the site.
The source turned out to be a compromised PHP file from another project hosted on the same shared server. The infection had spread silently, generating thousands of spam URLs that Google had begun crawling and indexing, pages that had nothing to do with the site and that, left unchecked, would have caused lasting reputational and ranking damage.
INDEXED AT DISCOVERY
Fraudulent spam URLs appearing in Google’s index under my domain
QUEDED FOR INDEXING
Additional malicious URLs pending in Search Console, not yet indexed but actively being crawled
DIAGNOSIS
The first step was not to start submitting removal requests. That would have been treating the symptom while the source continued generating new URLs. The priority was locating and eliminating the infection before anything else.
The instinct is to act immediately on what’s visible in Search Console. But submitting removal requests against an active infection is whack-a-mole, for every URL removed, new ones are generated. Containment had to come first, deindexing second.
I ran a deep manual inspection of the server file structure alongside Wordfence, a WordPress security plugin, to scan for modified or injected files. After a couple days of methodical investigation, I located the compromised PHP file. Once identified, I could map the full scope of the damage and plan the recovery sequence.
The malicious file was generating spam URLs following three distinct root paths. All 20,000+ indexed URLs and the 100,000+ queued fell into one of these three patterns, which meant a targeted blocking approach was viable rather than URL-by-URL removal.
The same shared hosting account contained other projects. A full server inspection revealed additional infected files across those projects, all of which needed to be addressed as part of the same remediation, not just the primary site.
STRATEGY APPROACH
The recovery required four distinct phases executed in a specific order. Doing them out of sequence, for example, starting deindexing before containment, would have wasted effort and potentially prolonged the damage.
Phase order: Contain → Block → Restrict → Accelerate. Each phase was a prerequisite for the next. Skipping or reordering any of them would have made the subsequent steps less effective or entirely ineffective.
This wasn’t a complex problem technically, it was a problem that required correct diagnosis and disciplined prioritization. The tools involved were all standard: .htaccess, robots.txt, Search Console, and XML sitemaps. The outcome depended entirely on the sequence in which they were used.
RECOVERY SEQUENCE
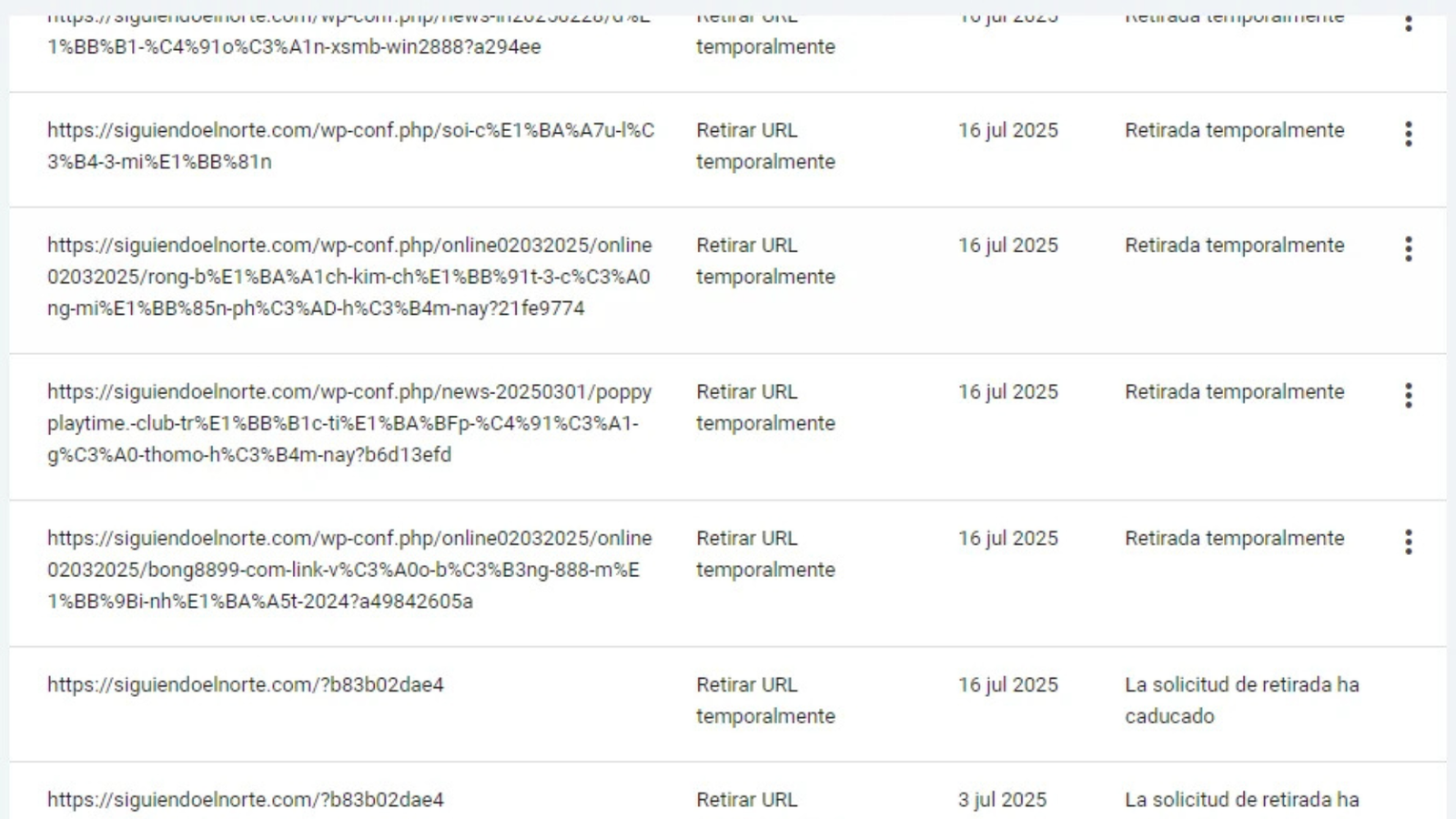
Deleted the compromised PHP file. Inspected and cleaned all other projects on the same hosting account. Changed all FTP, hosting panel, and database credentials. Activated daily automated security scanning via plugin. Until this step was complete, no other action made sense. I manually submitted close to 200 removal requests in Search Console, targeting key examples of the spam URLs. This served two purposes: reduce visibility of the malicious content and alert Google that something was off. [Pictures 1]
Since all malicious URLs followed just three root paths, I applied 410 Gone directives in .htaccess for each path. A 410 response tells search engines the content is permanently gone, stronger than a 404, and the correct signal for content that should never return.
Added Disallow directives in robots.txt for the same three paths. This prevented Googlebot from crawling the remaining queued URLs while the 410 signals propagated, reducing the volume of new crawl activity against URLs that would never contain legitimate content.
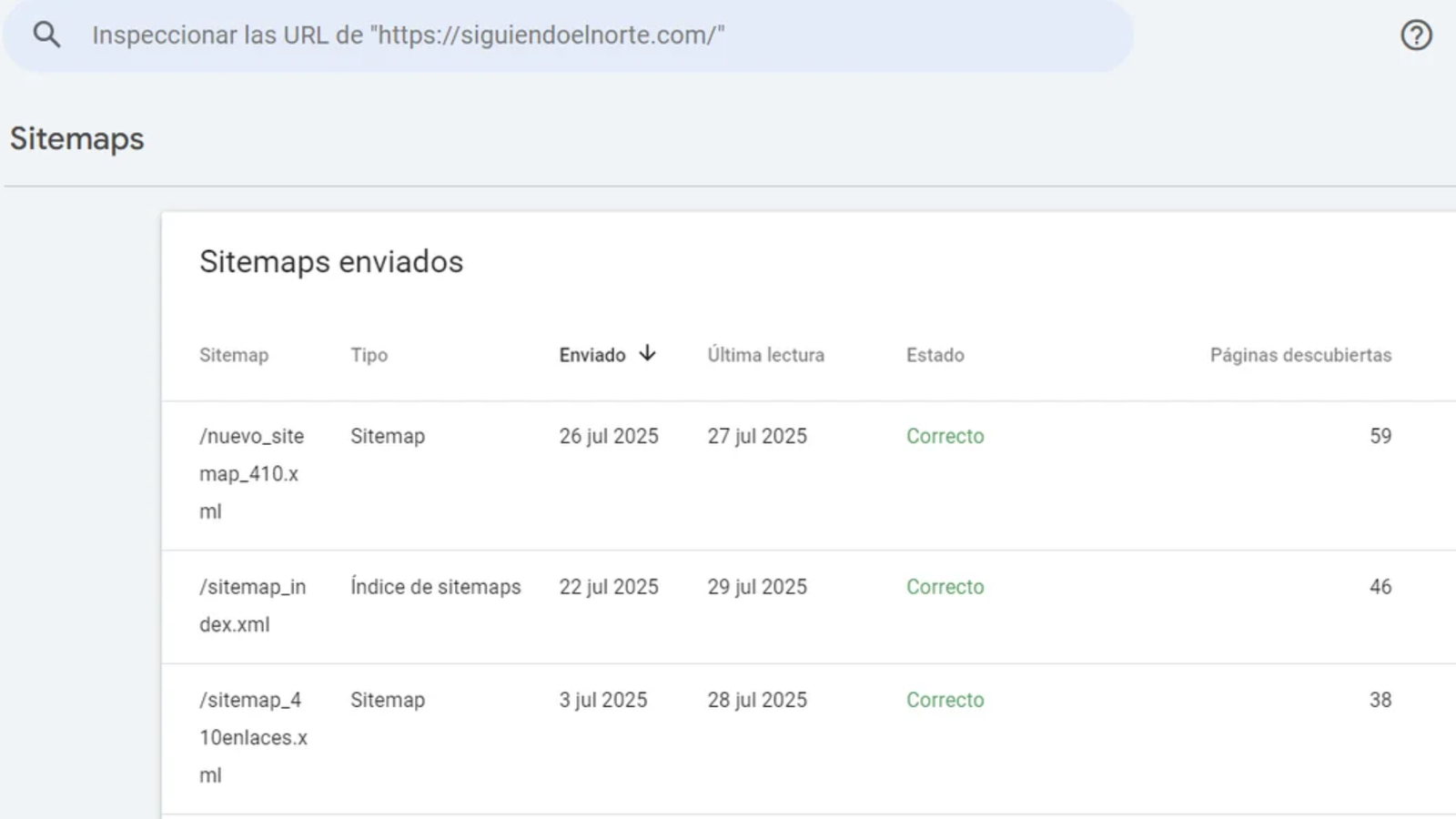
Once the indexed URL count had dropped from 20,000+ to under a few hundred through natural deindexing, I created a dedicated XML sitemap containing only the remaining malicious URLs, then temporarily removed the robots.txt Disallow directives. This forced Googlebot to recrawl those specific URLs immediately, encounter the 410 responses, and remove them from the index faster than passive deindexing would allow [Picture 2]. Once complete, the Disallow directives were reinstated.
RECOVERY SEQUENCE
8
Down from over 20,000 indexed at peak. The remaining 8 are in the final deindexing queue after 1-2 months wornking on it. The 138,000+ URLs that were blocked before indexing never became a live problem, they were contained at Phase 1 and never required individual remediation.
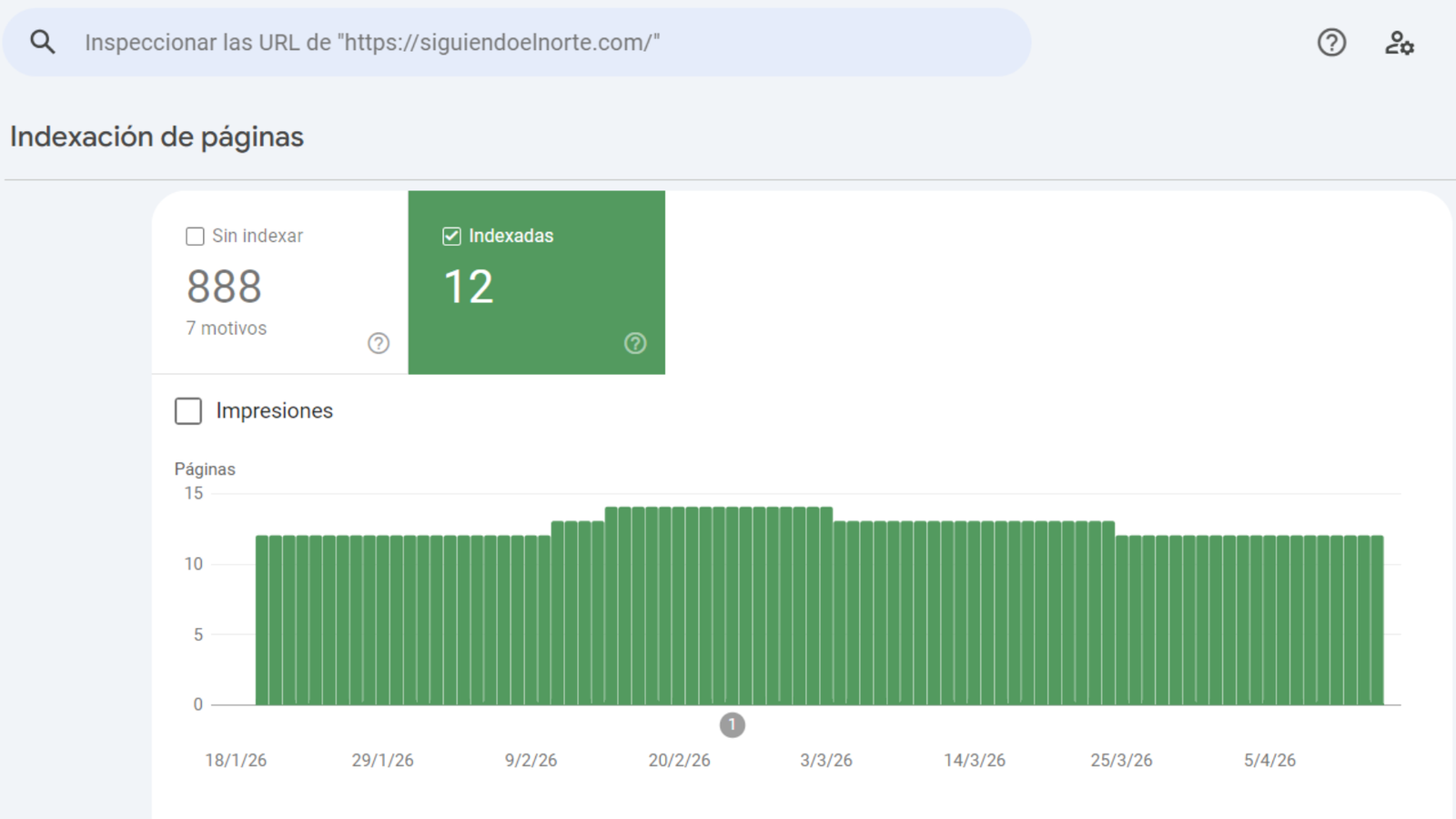
Today, the remaining URLs is 0 and the URLs blocked are 888 [Picture 3].
8
Down from over 20,000 indexed at peak. The remaining 8 are in the final deindexing queue after 1-2 months wornking on it. The 138,000+ URLs that were blocked before indexing never became a live problem, they were contained at Phase 1 and never required individual remediation.
Today, the remaining URLs is 0 and the URLs blocked are 888 [Picture 3].
TIME TO CONTAINMENT
Source identified and eliminated within days of discovery
INDEXED REDUCTION
From 20,000+ fraudulent URLs indexed to 8 remaining
TAKEWAYS